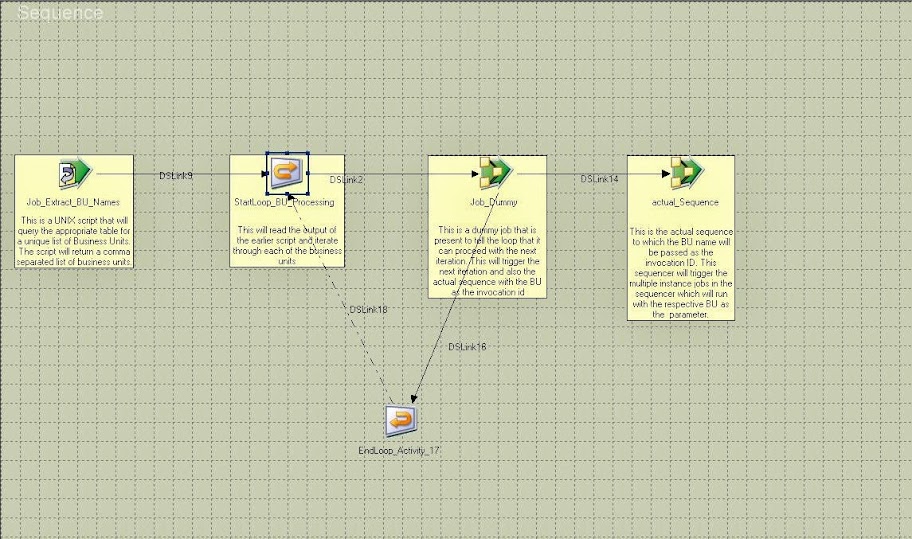
We have a set of multi-instance jobs that form a master sequencer. These jobs currently process data for multiple business units(BU) at one go. We are trying to separate the process for each BU and have them run in parallel through the same existing logic.
The names and number of BUs will decrease or increase based on business dynamics and we would like the DataStage flow to handle this.
The idea is to have one sequencer that will read the list of business units and pass the names of the BUs to the multiple instance jobs as parameters and process each instane in parallel. I created a very high level design. Can someone please improve on it or tell me if there's something amiss with the idea?
Below is the design.
Jerome
Data Integration Consultant at AWS
Connect With Me On LinkedIn
Life is really simple, but we insist on making it complicated.
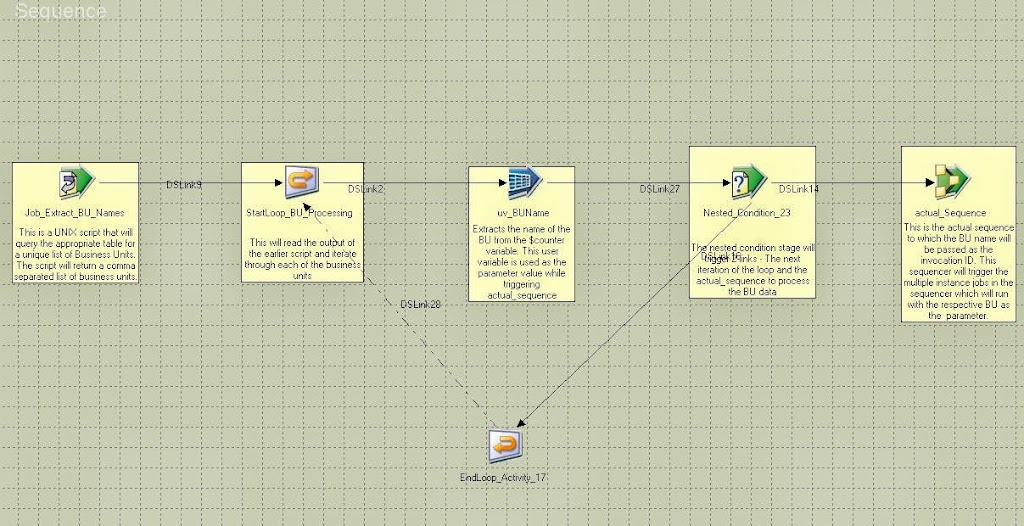
The actual_Sequence will only be executed once. You need to process the BU within the loop, passing the BU value via activity variable StartLoop_BU_Processing.$Counter
IBM Software Services Group
Any contribution to this forum is my own opinion and does not necessarily reflect any position that IBM may hold.
Here, the dummy job(which would basically do nothing) would run as part of the loop in every iteration. On successful completion, the dummy job will trigger the 2 subsequent links - the actual_sequence with eh start loop counter variable as a parameter and also the next iteration. This would ensure that multiple instances of actual_sequence will run in parallel for the different BUs.
Jerome
Data Integration Consultant at AWS
Connect With Me On LinkedIn
Life is really simple, but we insist on making it complicated.
That's not obvious in your master sequence design. At the very least more information (Annotations) required. Why do you want to "do nothing" a number of times? This too is not clear.
IBM Software Services Group
Any contribution to this forum is my own opinion and does not necessarily reflect any position that IBM may hold.
Agreed. The dummy job stage is really not required. Here is the updated design. The nested condition stage would trigger 2 links as mentioned in my earlier post. I think that this would trigger the actual_sequence for different BUs in parallel albeit with a slight delay in start time for each BU. Is my understanding right?
Jerome
Data Integration Consultant at AWS
Connect With Me On LinkedIn
Life is really simple, but we insist on making it complicated.
That's better, but the layout doesn't really jump out at me that actual_Sequence is in the loop (which I missed first time too). Perhaps a layout like this would make it clearer.