Page 1 of 1
Help DataStage in a public ETL benchmark test
Posted: Sat Mar 07, 2009 7:02 pm
by vmcburney
A French firm called ManApps is running a public benchmark comparing DataStage to Talend, Pentaho and Informatica. They don't know much about DataStage and have some design flaws. Have a look at this job and comment on how you would improve it and I will email feedback back to ManApps.
(For more background you can read my December blog post
ETL Benchmark Favours DataStage and Talend and my March update
ManApps ETL Benchmark Redux: Informatica Surges to Lead.)
Scenario:
Reading X lines from a file input delimited, looking up to another file input delimited, for 4 fields using id_client column. Writing the jointure result into a file output delimited.
Parallel Job Design:
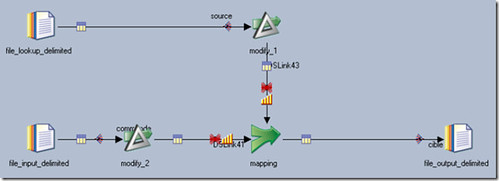
File_input_delimited has three fields, file_lookup_delimited has nine fields. There are four test cases based on increasing the row volume, in all four the lookup has 100K rows and the input has 100K, 1M, 5M and 20M rows.
How can this job be improved?
Posted: Sat Mar 07, 2009 8:41 pm
by sima79
Definately as you have posted in your blog, change the join to a lookup stage. I would also go with a 1 node configuration as well. I have had a look at the other parallel job designs and have no idea why they have chosen to use a join stage which requires a sorted input, given the number of rows in the reference file.
Another possible option is to separate the file I/O from the parsing of the columns using a sequential file and a column import stage.
Posted: Sun Mar 08, 2009 6:31 am
by ray.wurlod
Lose the repartitioning by moving the partitioning to the inputs of the Modify stage especially in a multiple-machine environment.
For larger volumes, reading the second file into a Lookup File Set may help. So might multiple readers per node.
I take it that the delimited file format is a given? Fixed-width format, if available, can be parsed faster.
Posted: Mon Mar 09, 2009 8:21 am
by stewarthanna
They should change to lookup.
Use Configuration files that match the volume, scaling from 1node to 2, 3, 4....using a larger config file will only incur startup time when processing small volumes
Remove unnecessary partitioning and sorting, lookup does not require it
Add -readers to Sequential File Stage to improve performance reading data, but I doubt this will be a bottleneck
Posted: Mon Mar 09, 2009 11:08 am
by rwierdsm
Thought I read somewhere that reading a sequential file as a single wide column and then doing a column split as the second stage makes the reads faster. Allows the column determination to happen in parallel instead of sequetial.
Rob
Posted: Mon Mar 09, 2009 12:24 pm
by priyadarshikunal
While using joiner also (Not a good option), modifying it a bit outperform informatica as there is marginal differnece. As Ray mentioned moving the partioning to the first link will help because its first partitioning and then repartioning.
Wonder if they are using stable sort or performing any thing inside modify stage.
Get rid of extra logging information and switch off job monitor.
and the best option would be to use lookup because it will love to handle 7 MB or 34MB or 68 MB (Test 12) of lookup file in whatever partition and with whatever number of nodes.
As they have mentioned that they changed job for informatica to use 1 partition for less number of records. why not used single node for less number of records. I think the startup time consists of around half of the time taken to process 100,000 records.
I would love to see the timings of all tools when running on data 10 times more than they are using now. but i can't see their machine much capable of handling that.
Posted: Mon Mar 09, 2009 3:08 pm
by ray.wurlod
Are you permitted to use a server job for small volumes?
Posted: Mon Mar 09, 2009 4:31 pm
by vmcburney
Good question - the benchmark has a set of results for server edition and parallel edition. The server job version has a hash file lookup. I will post a couple more job designs later including a server edition one.
Posted: Tue Mar 10, 2009 1:16 am
by balajisr
Interesting Post.
What does modify_1 do? Does it drops certain columns or renames column name? If it only drop columns we can use sequential file property "Drop on Input" instead of modify stage modify_1.
Setting Env variable APT_TSORT_STRESS_BLOCKSIZE variable to an appropriate value will speed up join for huge volumes.
Another option is to use lookup stage which is already mentioned.
Posted: Wed Jun 24, 2009 3:55 pm
by bobyon
I see this post is a little old and maybe I'm to late but how about putting in explicit sort stages so you can specify the amount of memory to use.