I'm writing a generic job that takes a table name and key column name as input parameters. The tables to process all have different key column names.
The job reads a table, performs some processing and then should write the updated record back to the table.
I can get this job to function correctly when doing inserts, but when a database update needs to be done the stage needs to know what the key column is and it seems that the RCP doesn't pass key column information onwards - thus the job aborts at runtime with the error message
"SQL_IL_Tabelle: Failed to generate where clause for update statement. No key fields defined in the design schema. "
I've tried several things to no avail, if I create a temporary column with the attribute "key" and later change it to the name of the real key column in a modify stage it doesn't work. The number and names of columns to be processed differs with each table and thus I can't think of a syntax in the UPDATE statement such as "UPDATE table SET({something}) WHERE KEY = #ParameterKeyColumn#", since that something can contain from 1 to 30 columns.
I'm open for suggestions since the alternative is to write (or clone) about 50 jobs for these files.
RCP and performing a database update
Moderators: chulett, rschirm, roy
 </a>
</a>-
kwwilliams
- Participant
- Posts: 437
- Joined: Fri Oct 21, 2005 10:00 pm
Re: RCP and performing a database update
For updates, I have given up on using RCP. The inherit weakeness is that the key must be defined in the design. In the past, I have done it passing two parameters - something like jpSet and jpWhere. The issue I had with it is all of the escape characters that I had to add to the values of the parameters. It made the job to difficult for the less than average resource to maintain, so I always write individual jobs to perform updates.
I hope someone else can provide more encouraging information on how they have accomplished this work.
I hope someone else can provide more encouraging information on how they have accomplished this work.
Keith Williams
keith@peacefieldinc.com
keith@peacefieldinc.com
After posting my question I have thought a bit more about the problem. In kwwilliams method I would need to store the record columns somewhere and pass them to the job, not a task I'd like to perform. I think that I might be able to do this using the generic stage and issuing the keys explicitly and will report if I have any success with that method, but I'm not sanguine about the chances of success and might have to locate someone in the project to copy the adapt the 50 jobs.
I've managed to solve the problem posted and it wasn't quite as onerous as I'd expected. The solution is to use a generic stage and use the parameter value in the statement there.
1. Write the output to the DB stage (whichever one you choose) using RCP but explicitly declaring the key column in an upstream stage.
2. Turn on $APT_DUMP_SCORE
3. run the job and copy out the part of the score for the DB stage.
4. replace the DB stage with a "generic" stage, and add in operator and options as copied from the score.
--> Remove leading and trailing single quotes from the options,
--> options are declared without the leading "-"
--> Replace all occurrences of backslash with empty
--> Locate your dummy key column text and replace with #Variable# containing the dynamic key column name
5. Compile & run!
1. Write the output to the DB stage (whichever one you choose) using RCP but explicitly declaring the key column in an upstream stage.
2. Turn on $APT_DUMP_SCORE
3. run the job and copy out the part of the score for the DB stage.
4. replace the DB stage with a "generic" stage, and add in operator and options as copied from the score.
--> Remove leading and trailing single quotes from the options,
--> options are declared without the leading "-"
--> Replace all occurrences of backslash with empty
--> Locate your dummy key column text and replace with #Variable# containing the dynamic key column name
5. Compile & run!
Being my first time using the Generic stage, I am a bit lost.
The Score didn't show me much; I assume you meant $OSH_DUMP
But I'm having a bit of trouble transcribing what I see in the OSH dump into the Generic stage.
If you have a moment, would you please post a copy of a few of the items as you saw them in the log, and then how they should appear in the Generic stage?
The Score didn't show me much; I assume you meant $OSH_DUMP
But I'm having a bit of trouble transcribing what I see in the OSH dump into the Generic stage.
If you have a moment, would you please post a copy of a few of the items as you saw them in the log, and then how they should appear in the Generic stage?
It can be a bit of work to get the stage working as expected.
First you need to write the job, preferable with RCP, but using your normal output stage. Once you have all the stage options correctly defined as you want them, turn on $OSH_DUMP and select the section that uses the stage you want to turn into a generic one, in my case the enterprise ODBC stage:
Now all that is necessary is to transpose these options into a generic stage. Each command line option turns into one generic stage line:
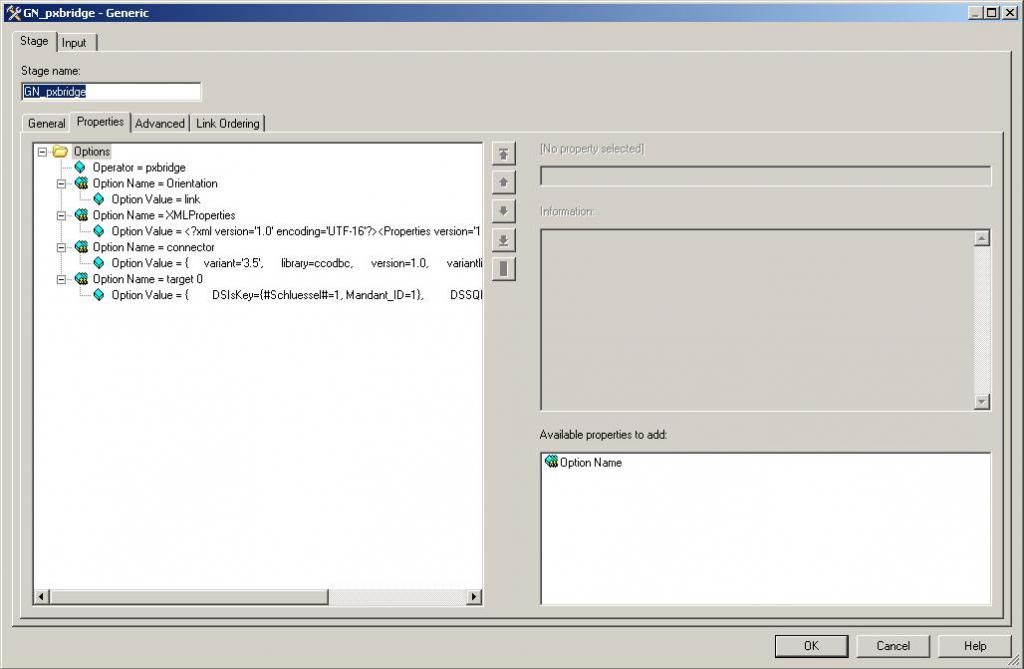
First you need to write the job, preferable with RCP, but using your normal output stage. Once you have all the stage options correctly defined as you want them, turn on $OSH_DUMP and select the section that uses the stage you want to turn into a generic one, in my case the enterprise ODBC stage:
Code: Select all
pxbridge
-Orientation link
-XMLProperties '<?xml version='1.0' encoding='UTF-16'?><Properties version='1.1'><Common><Context type='int'>2</Context><Variant type='string'>3.5</Variant><DescriptorVersion type='string'>1.0</DescriptorVersion><PartitionType type='int'>8</PartitionType><RCP type='int'>1</RCP><Reject><RejectErrorConditions><RejectErrorCondition type='int'>0</RejectErrorCondition></RejectErrorConditions><RejectDataElements></RejectDataElements></Reject></Common><Connection><DataSource modified='1' type='string'><![CDATA[VerBerA_SL]]></DataSource><Username modified='1' type='string'><![CDATA[datastage]]></Username><Password modified='1' type='string'><![CDATA[******]]></Password></Connection><Usage><WriteMode modified='1' type='int'><![CDATA[8]]></WriteMode><GenerateSQL modified='1' type='bool'><![CDATA[1]]></GenerateSQL><TableName modified='1' type='string'><![CDATA[dbo.V_KIS_AFVFahrzeuge]]></TableName><EnableQuotedIDs type='bool'><![CDATA[0]]></EnableQuotedIDs><SQL></SQL><TableAction collapsed='1' type='int'><![CDATA[0]]></TableAction><Transaction><RecordCount modified='1' type='int'><![CDATA[10000]]></RecordCount></Transaction><Session><IsolationLevel type='int'><![CDATA[1]]></IsolationLevel><AutocommitMode type='int'><![CDATA[0]]></AutocommitMode><ArraySize modified='1' type='int'><![CDATA[500]]></ArraySize><SchemaReconciliation><FailOnSizeMismatch modified='1' type='bool'><![CDATA[0]]></FailOnSizeMismatch><FailOnTypeMismatch modified='1' type='bool'><![CDATA[0]]></FailOnTypeMismatch><FailOnCodePageMismatch type='bool'><![CDATA[0]]></FailOnCodePageMismatch><DropUnmatchedFields modified='1' type='bool'><![CDATA[0]]></DropUnmatchedFields></SchemaReconciliation><CodePage collapsed='1' type='int'><![CDATA[0]]></CodePage><FailOnRowErrorPX type='bool'><![CDATA[1]]></FailOnRowErrorPX></Session><Logging><LogColumnValues modified='1' type='bool'><![CDATA[1]]><LogKeysOnly type='bool'><![CDATA[0]]></LogKeysOnly><Delimiter modified='1' type='int'><![CDATA[3]]></Delimiter></LogColumnValues></Logging><BeforeAfter collapsed='1' type='bool'><![CDATA[0]]></BeforeAfter></Usage></Properties >'
-connector '{
variant='3.5',
library=ccodbc,
version=1.0,
variantlist='3.5',
versionlist='1.0',
name=ODBCConnector
}'-
SettValleyConsulting
- Premium Member

- Posts: 72
- Joined: Thu Sep 04, 2003 5:01 am
- Location: UK & Europe
Just came across this and thought I'd post an alternative:- If your target is Oracle, you can retrieve the column list from the metadata table all_tab_columns. It's not pretty, but here is some working code, this generates a SQL statement which is written to a file used as the SQL file in the update stage.
Key column names are in parameter pTableKeyNames, pTrgSchema is the target schema and pTablename the target table:
You can make it even more generic by retrieving the list of key columns from Oracle also...
Key column names are in parameter pTableKeyNames, pTrgSchema is the target schema and pTablename the target table:
Code: Select all
SELECT 'UPDATE #pTrgSchema#.#pTableName# SET ' from dual
UNION ALL
select set_row || ( CASE WHEN rownum=cnt then ' ' else ', ' end) set_row
from
(
select
column_name || '=ORCHESTRATE.' || column_name set_row,
(select Count(*) - #pKeyNo# from all_tab_columns where table_name = '#pTableName#' and owner='#pTrgSchema#') cnt
from all_tab_columns where table_name = '#pTableName#' and owner='#pTrgSchema#'
and instr('#pTableKeyNames#', column_name) = 0
order by column_id
)
UNION ALL
SELECT 'WHERE ' from dual
UNION ALL
select set_row || ( CASE WHEN rownum=#pKeyNo# then ' ' else ' AND ' end) set_row
from
(
select
column_name || '=ORCHESTRATE.' || column_name set_row
from all_tab_columns where table_name = '#pTableName#' and owner='#pTrgSchema#'
and instr('#pTableKeyNames#', column_name) > 0
order by column_id
)
UNION ALL
SELECT ';' from dualCode: Select all
SELECT cols.table_name, cols.column_name
FROM all_constraints cons, all_cons_columns cols
WHERE cols.owner = '#pTrgSchema#'
AND cons.status = 'ENABLED'
AND cons.constraint_type = 'P'
AND cons.constraint_name = cols.constraint_name
AND cons.owner = cols.owner;Phil Clarke
